

RVC (Retrieval-based-Voice-Conversion) のモデル作成や、リアルタイム音声変換に関する知見が溜まったので、自分用のメモも兼ねてここに共有します。
なお、本記事は RVC のバージョン 2.2.231006 を基に作成しています。
RVC とは
機械学習ベースの音声変換技術です。
学習が簡単かつ高速で、少量のデータによる学習でも良好な結果が得られることが特徴とされています。
RVC WebUI 導入
GitHub から最新のバージョンをダウンロードします。
ファイルを任意の場所に展開し、go-web.bat を起動します。
しばらくするとブラウザで RVC の画面が開きます。
RVC モデル作成
データの準備
変換先の声が含まれる音声データを用意します。
音声データの長さは、10 ~ 50 分が推奨されています。
いくつかの長さで試したところ、10 分ではあまり安定せず、30 分あれば充分、2 時間でもそれほど品質は上がらない、という印象です。
無音の時間があっても学習前に自動でカットされるため、特に問題はありません。
BGM や効果音が入っている場合は、次の項で説明する音声抽出を行います。
その際、音声データの時間が長いと後述の問題が発生するため、事前に 20 ~ 30 分毎に音声データを分割しておくことをお勧めします。
音声抽出 (必要に応じて)
BGM や効果音を取り除いて、学習に適した音声データに変換します。
RVC を起動して、「伴奏ボーカル分離 & 残響除去 & エコー除去」と書かれたタブをクリックします。
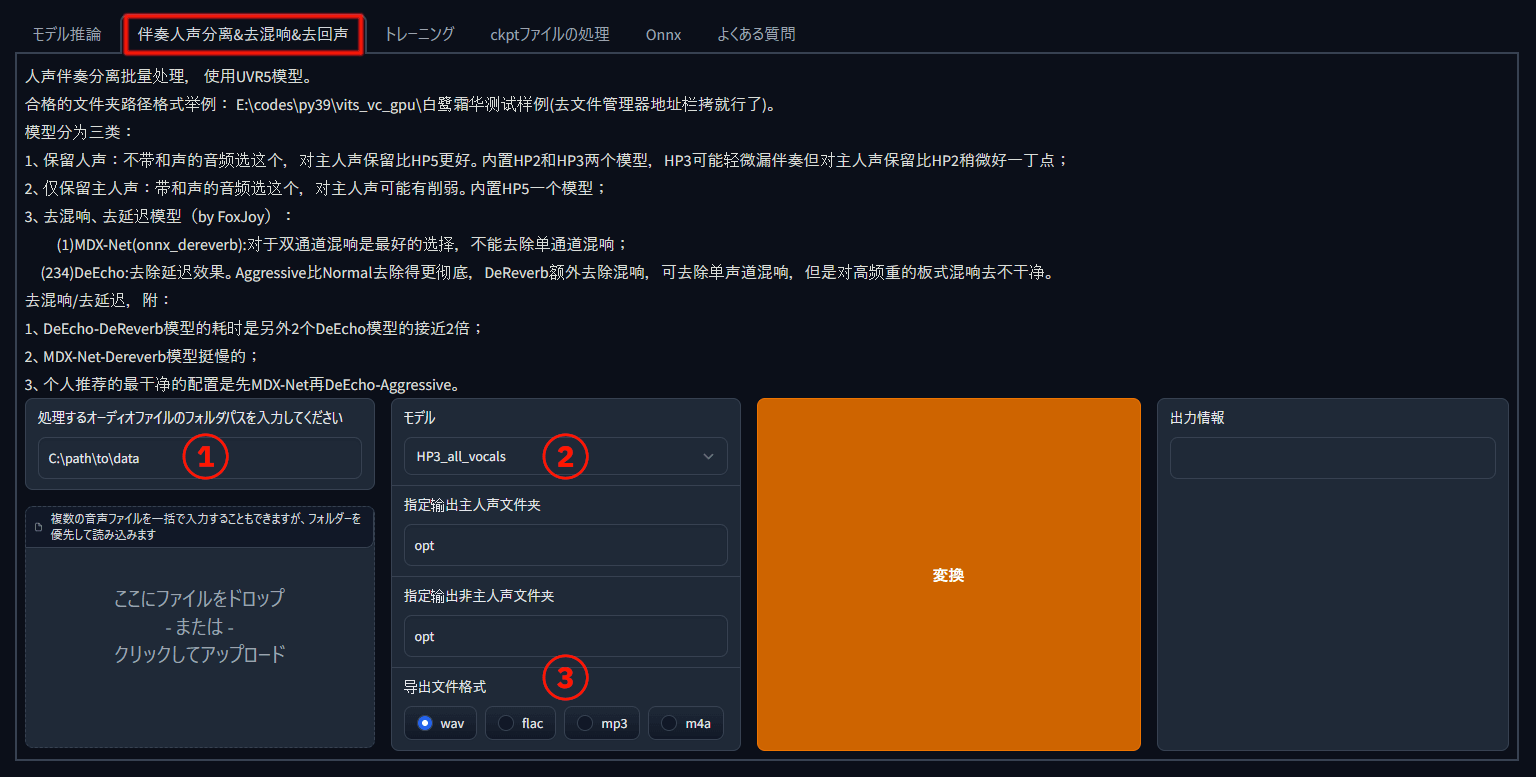
画像の 1, 2, 3 の部分を変更します。
-
音声データを入れたフォルダのパス
フォルダ名やファイル名にスペースが含まれると処理に失敗するようです。
-
モデル
-
データに対象の声以外の声が含まれない場合 :
HP2orHP3を選択HP3はHP2より非音声が入る可能性があるが、音声は綺麗に残りやすいらしい。お好みで。 -
データに対象の声以外の声が含まれる場合 :
HP5を選択楽曲などをデータにする場合はこちらを選びます。
-
-
出力形式
学習時に wav に変換されるので、この段階で wav を選んでおきます。
「変換」をクリックしてしばらく待つと、opt フォルダの中に変換後の音声データが出力されます。
音声抽出を行った結果、変換後の音声にエコーがかかる場合があります。
その場合は、2 のモデル選択で onnx_dereverb_By_FoxJoy を指定し、抽出後の音声に対してエコー除去を行います。
学習
RVC を起動して、「トレーニング」と書かれたタブをクリックします。
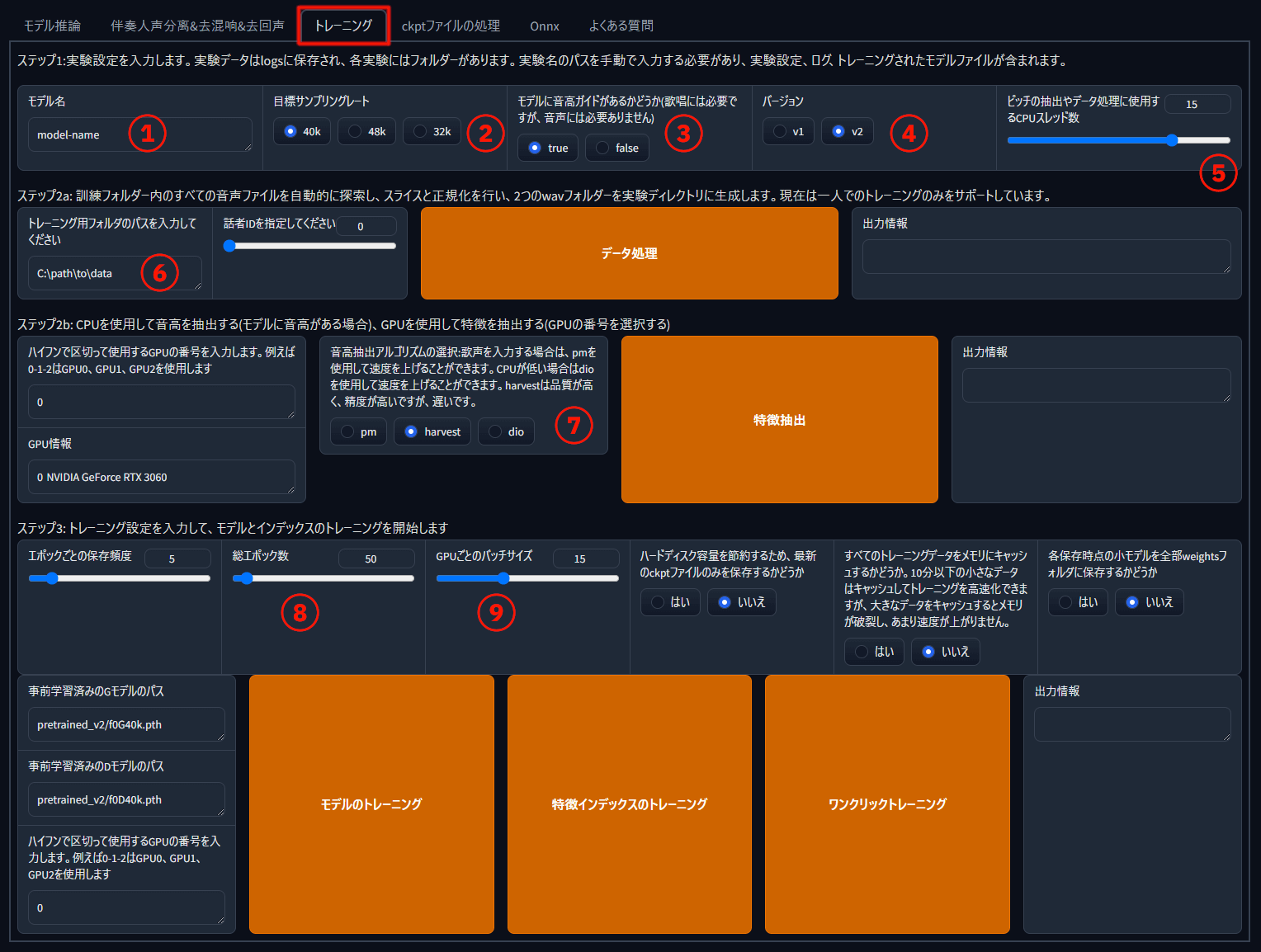
画像の 1 ~ 9 の部分を変更します。
-
モデル名
任意の名前を付けます。
-
目標サンプリングレート
高ければ良いというわけではなく、学習データの品質に合わせて選ぶ。
-
高音ガイド
trueを選択。 -
バージョン
v2を選択。 -
CPU スレッド数
上げると処理が速くなる。
(CPU の論理プロセッサ数) * 0.6くらいが良さそう。 -
音声データを入れたフォルダのパス
フォルダ名やファイル名にスペースが含まれると処理に失敗するようです。
-
音高抽出アルゴリズム
rmvpeまたはrmvpe_gpuを選択。 -
総エポック数
値に比例して学習時間が長くなる。
学習データの品質が良くない場合は20~30が推奨、品質が高く十分な量がある場合は200まで行けるらしい。
ひとまず20で作成し、出来が良かったら値を上げてさらなる向上を狙うのが良さそう。 -
GPU ごとのバッチサイズ
バッチサイズを上げると学習時間が短くなる。
値に比例して VRAM の使用量が増えるので、容量と相談して設定する。
VRAM 12 GB の RTX 3060 で、15までは問題なく設定できた。
設定出来たら「ワンクリックトレーニング」をクリックしてしばらく待ちます。
学習にかかる時間は GPU のスペックや学習データの量、設定によって変わります。
学習が完了したら、weights フォルダに生成された XXX.pth ファイル、logs フォルダに生成された added_XXX.index ファイルを保存しておきます。
リアルタイム音声変換
作成したモデルを使ってリアルタイムに音声変換する方法を紹介します。
VB-CABLE 導入
Discord やゲームのボイスチャットなどで使用する場合、変換後の音声をマイク入力に流すため、VB-CABLE を使用します。
変換後の音声をスピーカーで聴くだけの場合、この項はスキップして OK です。
公式サイト から最新版をダウンロードし、任意の場所に展開します。
VBCABLE_Setup_x64.exe を実行し、ドライバをインストールします。
インストール後、システムのサウンド設定から、出力と入力にそれぞれ CABLE Input と CABLE Output が追加されていることを確認します。
VB-CABLE 使用時は、RVC GUI の出力先 (スピーカー) を CABLE Input に設定し、Discord やゲームの入力元 (マイク) を CABLE Output に設定します。
逆に設定しても動作しないので注意してください。
RVC GUI
VC Client を使ったリアルタイム音声変換が多く紹介されていますが、ここでは RVC 付属の RVC GUI を使う方法を紹介します。
go-realtime-gui.bat を起動します。
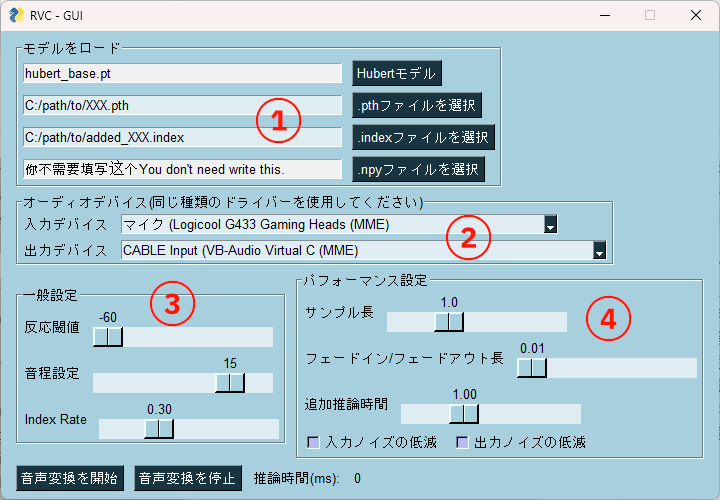
画像の 1 ~ 4 を変更します。
3 と 4 については、2 の出力デバイスをスピーカーにして、自分で聴きながら調整すると良いでしょう。
-
モデル選択
作成した
XXX.pthファイルとadded_XXX.indexファイルを選択します。 -
オーディオデバイス
入力デバイスに使用するマイクを指定し、出力デバイスに
CABLE Inputを指定します。
いくつかのドライバが選択できるので、マイク入力が検知されるものを選択します。
筆者の環境ではMMEが使用できました。 -
一般設定
-
反応閾値
値を下げるほど反応が高感度になり、小さな音まで入力されるようになります。
-
音程設定
出力音声の音程を変更します。
12で 1 オクターブ上がります。 -
Index Rate
値を上げると音程の変化が学習元に近付きますが、上げ過ぎると言葉が聞き取りづらくなります。
-
ピッチアルゴリズム
rmvpeを選択。
-
-
パフォーマンス設定
-
サンプル長
値を上げると変換の品質が上がるかわりに遅延が増えて、リアルタイム性が下がります。
0.5 くらいが品質と遅延のバランスに優れていると感じました。 -
追加推論時間
サンプル長と同様に、値を上げると変換の品質が上がり、遅延が増えます。
サンプル長ほどは品質も遅延も変化しません。 -
ノイズの低減
入れない方が変換の品質が良いです。
-
「音声変換を開始」をクリックすると変換が始まります。
まとめ
RVC モデルの作成方法と、作成したモデルによるリアルタイム音声変換の方法を紹介しました。
モデルの品質が向上する学習設定や、より高品質で遅延の少ない変換方法が判明したら、また更新しようと思います。
